INTRODUCTION
In this blog, we will discuss about the 4.4BSD Thread scheduler one of the two schedulers in NetBSD and a few OS APIs that can be used to control the schedulers and get information while executing.
Few basics
What is a scheduler?
A Process Scheduler schedules the processes of different states namely ready, waiting, and running. There are different scheduling algorithms like :
- Shortest Job first
- First Come First Serve
- Shortest Remaining time first
- Priority scheduling
- Round robin
- Multi-level queue scheduling etc.,
These algorithms are either non-preemptive or preemptive. In preemptive scheduling is based on priority where a scheduler may preempt a low priority running process anytime when a high priority process enters into a ready state, whereas in non-preemptive scheduling once a process enters running state it cannot be preempted until it completes its allotted time.
NetBSD’s internals
Before going into the schedulers in NetBSD lets learn about few internals of NetBSD.
Processes:
NetBSD supports traditional processes created by fork() and native POSIX threads (pthreads). The threads are implemented with a 1:1 threading model where each user thread (pthread) has a kernel thread called a light-weight process (LWP). So, Inside the kernel, both processes and threads are implemented as LWPs and are served the same by the scheduler.
Scheduling classes:
According to the POSIX standard, at least the following three scheduling policies (classes) should be provided to support the POSIX real-time scheduling extensions:
- SCHED OTHER: Time-sharing (TS) scheduling policy, the default policy in NetBSD.
- SCHED FIFO: First in, first-out (FIFO) scheduling policy. *
- SCHED RR: Round-robin scheduling policy. *
(* - strictly provided by the standard.)
CSF:
CFS is a Common Scheduler Framework which was introduced in NetBSD 5.0. It provides an Interface for implementing different thread scheduling algorithms and one among those schedulers can be selected at compile-time. Currently, there are 2 schedulers available, they are
- 4.4BSD thread scheduler: The traditional BSD’s scheduler.
- M2 scheduler: A more advanced thread scheduler.
Controlling the scheduling of processes and threads
NetBSD provides utilities to control and change scheduling policies and thread affinity. We are going to see about schedctl and cpuctl in detail.
Schedctl
The schedctl command can be used to control the scheduling of processes and threads. It also returns information about the current scheduling parameters of the process or thread. This enables us to monitor and control scheduling in NetBSD, including changing the priority , affinity, scheduler’s - policy. Etc,
1. We can see the scheduling information of a process by it’s PID.
#schedctl -p 18467
LID: 1
Priority: 43
Class: SCHED_OTHER
Affinity (CPUs): <none>The ‘Class’ in the above prompt refers to the scheduling policy the process is being scheduled with. We have 3 scheduling policies SCHED_OTHER, SCHED_FIFO,SCHED_RR
2. We can change the scheduling policy for a process or a command.
# schedctl -C SCHED_FIFO topAnd the top runs with FIFO policy whenever called.
Cpuctl
This can be used to control the CPU of the Computer. We can perform several operations like sending a cpu offline and bringing it back online, setting microcode and listing available cpus. Let’s see some examples.
1. This argument list can be used to see the available CPUs and their status.
$ cpuctl list
Num HwId Unbound LWPs Interrupts Last change Intr
---- ---- ------------ ---------- ------------------------ --------
0 0 online intr Tue Apr 7 23:17:32 2020 8
1 1 online intr Tue Apr 7 23:17:32 2020 02. We can see specific information regarding a cpu. It provides a lot of information, only a few interesting stats are mentioned here.
$ cpuctl identify 0
cpu0: highest basic info 00000016
cpu0: highest hypervisor info 00000000
cpu0: highest extended info 80000008
cpu0: Running on hypervisor: unknown
cpu0: "Intel(R) Core(TM) i5-8259U CPU @ 2.30GHz"
cpu0: Intel 7th or 8th gen Core (Kaby Lake, Coffee Lake) or Xeon E (Coffee Lake) (686-class), 2304.00 MHz
cpu0: L2 cache 256KB 64B/line 4-way
cpu0: L3 cache 6MB 64B/line 12-way
cpu0: 64B prefetching
cpu0: L1 1GB page DTLB 4 1GB entries 4-way3. We can send specific CPUs offline and online.
$ cpuctl offline 1
$ cpuctl list
Num HwId Unbound LWPs Interrupts Last change Intr
---- ---- ------------ ---------- ------------------------ -------
0 0 online intr Tue Apr 7 23:17:32 2020 8
1 1 offline intr Wed Apr 8 03:27:12 2020 0
$ cpuctl online 1
$ cpuctl list
Num HwId Unbound LWPs Interrupts Last change Intr
---- ---- ------------ ---------- ------------------------ -------
0 0 online intr Tue Apr 7 23:17:32 2020 8
1 1 online intr Wed Apr 8 03:27:59 2020 0In addition to these we can change affinity of a process and many other commands are available that can come handy to examine the scheduling policies and study threads and processes in NetBSD.
Process structure
As discussed before threads and processes are treated the same as LWPs by the scheduler. So the BSD associates a process ID with each thread, rather than with a collection of threads sharing an address space. For more detailed information regarding Process Structure please go through the book ‘The Design and Implementation of 4.4BSD Operating System’.
WORKING OF BSD SCHEDULER
4.4BSD scheduler
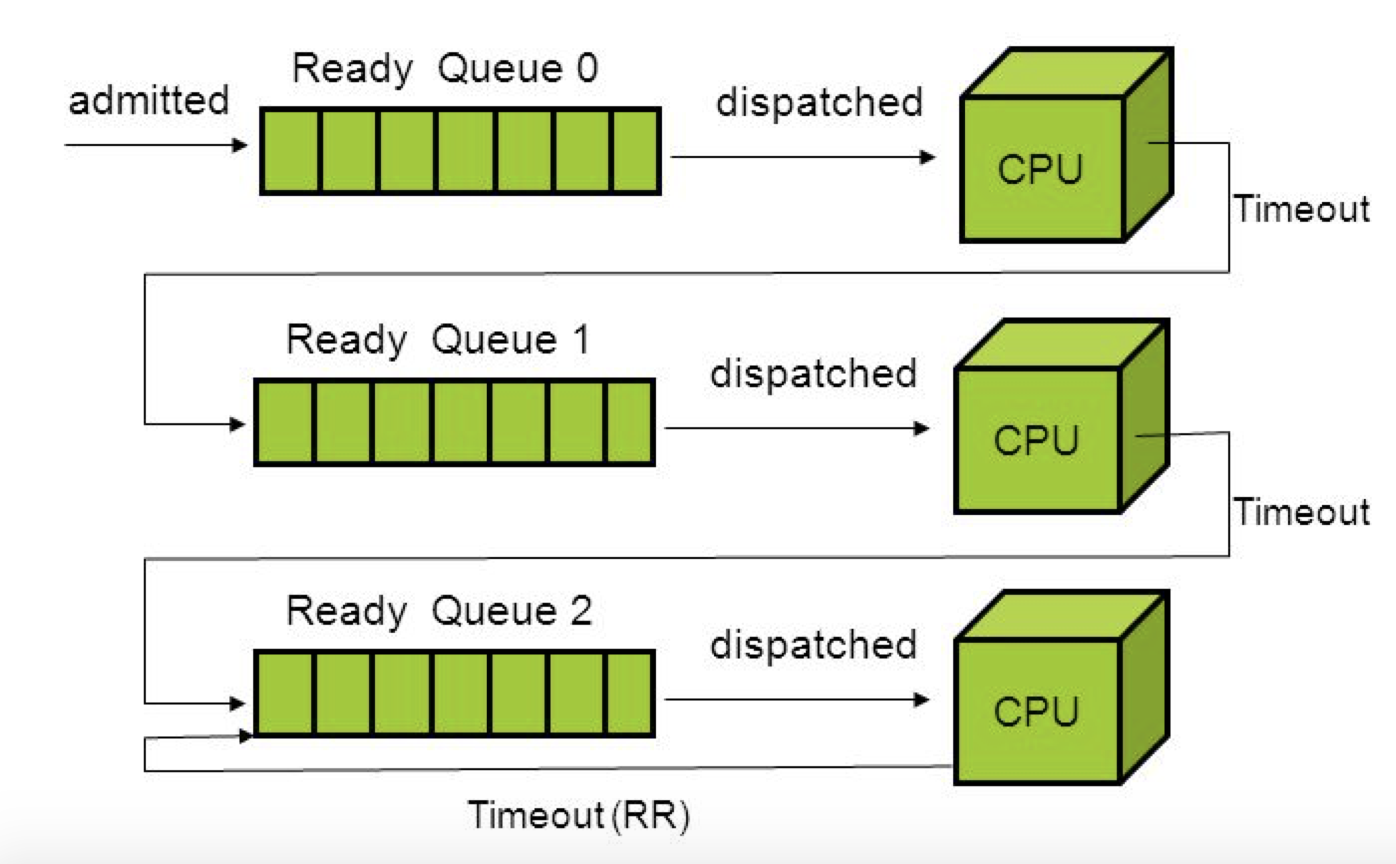
The traditional 4.4BSD scheduler employs a multi-level feedback queues algorithm, favoring interactive, short-running threads to CPU-bound ones.
 src: https://images.slideplayer.com/16/5138416/slides/slide_1.jpg
src: https://images.slideplayer.com/16/5138416/slides/slide_1.jpg
Multilevel feedback queue:
The multi-level feedback queue is an excellent example of a system that learns from the past to predict the future. This type of scheduler maintains several queues of ready-to-run threads, where each queue holds threads with a different priority as shown in the figure. At any given time, the scheduler chooses a thread from the highest-priority non-empty queue. If the highest-priority queue contains multiple threads, then they run in the Round-robin order. The time quantum used in 4.4BSD is 0.1 seconds.
Niceness
Each thread has an integer nice value, that determines how nice a thread is treated than other threads. A nice of zero does not affect thread priority. A positive nice, to the maximum of 20, decreases the priority of a thread and causes it to give up some CPU time it would otherwise receive. On the other hand, a negative nice, to the minimum of -20, tends to take away CPU time from other threads.
Priority
CPU time is made available to processes according to their scheduling priority. A process has two scheduling priorities, one for scheduling user-mode execution and one for scheduling kernel-mode execution. The p_usrpri field in the process structure contains the user-mode scheduling priority, whereas the p_priority field holds the current kernel-mode scheduling priority. Priorities are divided as shown in the figure in the range between 0 and 127, with a lower value interpreted as a higher priority.

Priority distribution
Calculating priority
As we have seen how priorities are divided let’s get into how actually are they calculated. The processes’ priority is determined by two values:
- p_estcpu : Time average value of CPU ticks (p_cpticks)
- p_nice : Process “nice” value with range of [ -20 to +20 ]
A process’s user-mode scheduling priority is calculated every four clock cycles (~= 40ms) using the following equation.
EQ1: p_usrpri = PUSER + ( p_estcpu / 4 ) + 2 p_nice
Values less than PUSER are set to PUSER (see Table) values greater than 127 are set to 127. This calculation causes the priority to decrease linearly based on recent CPU utilization. The user-controllable p_nice parameter acts as a limited weighting factor. Negative values retard the effect of heavy CPU utilization by offsetting the additive term containing p_estcpu. Otherwise, if we ignore the second term, p_nice simply shifts the priority by a constant factor.
The p_estcpu is adjusted for every one second via a digital decay filter (which reduces the effect of previous values by mathematical operations like a decay). The decay causes about 90 percent of the CPU usage accumulated in a 1-second interval to be forgotten over a period of time that is dependent on the system load average. To be exact, p_estcpu is adjusted according to EQ2 . Where the load is a sampled average of the sum of the lengths of the run queue and of the short-term sleep queue over the previous 1-minute interval of system operation. We will discuss about run queues below.
EQ2: p_estcpu = ( 2 load ) / ( 2 load + 1 ) p_estcpu + p_nice
The working of the decay filter is explained in detail in the book [The Design and Implementation of the 4.4BSD Operating System] but we are not going to cover it here.
Assigning priorities
As discussed the runnable processes get their priorities adjusted periodically, but what about the processes that were blocked awaiting an event?
The system ignores such processes, so an estimate of their filtered CPU-usage is calculated, and the priority adjusted accordingly. The system recomputes a process’s priority when that process is awakened and has been sleeping for longer than 1 second. This optimization can reduce the system’s overhead when many blocked processes are present. For this we use p_slptime and estimation of the process’s filtered CPU-usage can be done in one step with the help of this.
What is p_slptime
This is an estimate of the time a process has spent blocked waiting for an event. When a process calls sleep() this p_slptime is set to 0, while the process stays in SSLEEP or SSTOP state it is incremented once per second. When the process is awakened, the system calculates the p_estcpu with EQ3
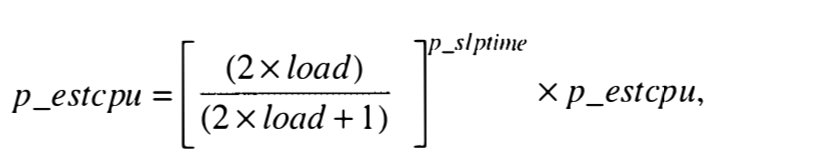
And then recalculates the scheduling priority using EQ1. This analysis ignores the influence of p_nice, and the load used is current avg load rather than the load at the time the process was blocked.
Process priority routines
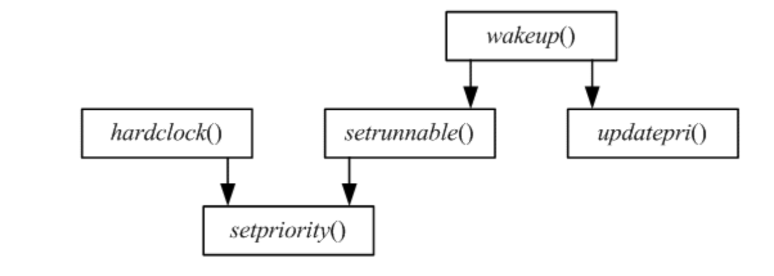
These are the procedural interface to the priority calculation.
Process Run Queues and Context Switching
The scheduling priority ranges between 0 and 127, with 0 to 49 reserved for processes executing in kernel mode, and 50 to 127 reserved for processes executing in user mode.
The system uses 32 run queues, selecting a run queue for a process by dividing the process’s priority by 4. The run queues contain all the runnable processes in main memory except the currently running process. The head of each run queue is kept in an array; associated with this array is a bit map, whichqs, that is used in identifying the nonempty run queues.
Two main routines for managing the queues:
- setrunqueue()
- rmrq()
The context switch is divided into two types
- miswitch() — machine-independent
- Cpuswitch() — machine dependent
Let’s observe the importance of each function.
cpu_switch(): the heart of the scheduling algorithm and is responsible for selecting a new process to run, and it operates as follows:
-
Block interrupts, then look for a nonempty run queue. Locate a nonempty queue by finding the location of the first nonzero bit in the whichqs bit vector. If whichqs is zero, there are no processes to run, so unblock interrupts and loop; this loop is the idle loop.
-
Given a nonempty run queue, remove the first process on the queue.
-
If this run queue is now empty as a result of removing the process, reset the appropriate bit in whichqs.
-
Clear the curproc pointer and the want_resched flag. The curproc pointer references the currently running process. Clear it to show that no process is currently running. The want_resched flag shows that a context switch should take place; it is explained in next part
-
Set the new process running and unblock interrupts.
mi_switch(): It contains the machine independent part of the context-switching code. Which is called when a process wants to sleep().
Now we have mi_switch(), priority calculations, but we need a mechanism for forcing an involuntary context switching.
- Voluntary context switches occur when a process calls the sleep() routine.
Sleep() can be invoked by only a runnable process, so sleep() needs only to place the process on a sleep queue and to invoke mi_switch() to schedule the next process to run. mi_switch() can’t be called by a process that is in interrupt state, because it must be called with in the context of a running process. -
The new mechanism is handled by the machine-dependent need_resched() routine, which generally sets a global reschedule request flag, named want_resched, and then posts an asynchronous system trap (AST) for the current process.
when a process is woken up and if it comes across an AST trap it requests for reschedule instead of resuming the process execution.
The 4.4 BSD scheduler doesn’t support preemptions in kernel mode. So the drawback here is it is not. Real Time scheduler.
This is about the 4.4BSD Scheduler, Let’s learn about the advanced M2 Scheduler in the second part.
References: